Home
New AI clips April 23th 2024
- Details
- Written by: Super User
- Category: IA clips
- Hits: 4132
I ll update this message a while, to post new clips
Latest news of the website April, 23th 2024
- Details
- Written by: Super User
- Category: IA clips
- Hits: 5741
If you are wondering if this website is still alive... well it is...
Right now, i am mostly generating video with Diffex and LCM models.
I keep the website that you are reading for the main articles only, so meanwhile i am still doing updates on my CivitAi page. Where i post my test content. If you are not an user of CivitAi, i suggest you to register, because you are not going to be able to see all the content there without an account. I find the criterias of CivitAi at bit questionnable, sometimes.

Meanwhile, i've decided to post some series of clips to train myself how to do better clips. (Comment about that: the videos on civitai have usually a better quality, it is just that i don't try to put music on civitAI).
Here are some shorts that i published on youtube:
Latest news of the website [updated: 03.07.23]
- Details
- Written by: Super User
- Category: IA clips
- Hits: 8120
I discovered recently some cool LCM models that i can use with DiffEx / AnimateDiff-CLI-Prompt-Travel, like Paradigm-LCM or the AnimateDiff-LCM Motion Model.
Thanks to this i was able to generate this video:
Make your own songs with SunoAI
- Details
- Written by: Super User
- Category: Music Generation
- Hits: 4646

The thumbnail above redirects to SunoAi
I actually had 30 good minutes of fun thanks to SunoAI
If you want to know why, click on "Read more"
Where to see demos of Sora Videos + prompts for Sora?
- Details
- Written by: Super User
- Category: Text-to-Video
- Hits: 9252
Where to see demos of Sora Videos + prompts for Sora?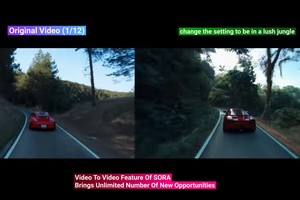
Click on the thumbnail above for 12 samples video created with Sora.
Sora, the text-to-video model (not the character of Kingdom heart), is the big news of the moment in the text generation AI world.
For some reasons, Sora attracted more attention than Google's VideoPoet, another text2video project, that is pretty impressive too and that was just released maybe 10 days before Sora.
Read more: Where to see demos of Sora Videos + prompts for Sora?
Funny Little clips (02 10 24)
- Details
- Written by: Super User
- Category: IA clips
- Hits: 4645


2 Funny little fake clips
They deserve some traffic
WW3: Shrooms fire and metal (short music clip)
- Details
- Written by: Super User
- Category: IA clips
- Hits: 5080

AI video generation is still under intensive development and I feel that for that moment and the technology and the technics to use it are not yet mature.
The technics are still progressing and some new tools are being released:
Making animations with just the prompt - a bit hard but possible
- Details
- Written by: Super User
- Category: IA clips
- Hits: 6074

I am trying to find tricks to adujst the video to the prompt, so you are less in the darkness while trying to enhance it. It is a time consuming process, probably useful to know to fix problems. For the moment, i can't tell how far this can be improved. I have several ideas.
How to do ? Article coming soon...
DiffEx part 2: How to create a video from a video thanks to DiffEx ?
- Details
- Written by: Super User
- Category: vid2vid
- Hits: 9148

If you click on the picture above, you will be redirected
to the post where i published this video for the first time.
I was asked how i did the very specific part of the video where i use the face of the woman of the original video to create the content.
If you don't know what this is all about, read this post on github. Or click on the thumbnail above.
Read more: DiffEx part 2: How to create a video from a video thanks to DiffEx ?
Page 3 of 7