
This tutorial is going to use PrivateGPT as a tool to interrogate a youtube video. Since PrivateGPT is able to read documents, if we can convert a youtube video to a document, we can interrogate the youtube video.
Youtube offers transcripts of the videos that appears usually one or two hours after a video has been uploaded.

The idea is then to copy this transcript where it should go (the subfolder "source_documents" where PrivateGPT is installed).
Of course, the transcript is an approximation of the content of a video and for example but not limited:
- From time to time, some words are inaccurate in the transcript and you can't understand the transcript while you can understand the video.
- Some puns make only sense orally and can't easily be translated to text.
- The transcript doesn't describe what happens on the screen
So, it is certainly possible to do better than what i do now, but it is already not bad.
So, to make this work, you need first to install PrivateGPT, which is a Python project, so i will consider later that you already have Python and that you know how to install packages with the pip installer. If you are looking for a tutorial to install PrivateGPT, follow this one. I followed it myself.
- Then i suggest you to go to the folder "source_documents" of PrivateGPT to remove all the documents that are unrelated to the questions you are gonna ask.
- If you have a "db" subfolder, i recommend to delete its content.
- Then you could just copy and paste the transcript of a video in a file, but it would be tedious. To make the things easier, i create this source code written in Python to download it and save it to the folder "source_documents":
import json
import yt_dlp
import string
import sys, os
from urllib import request
savdir="D:\\[your folder location\\privateGPT\\source_documents\\"
# please enter the location of the "source_documents" folder of privateGPT
# please use \\ on windows, to separate the directories.
if len(sys.argv)==0:
print("A youtube url is needed")
sys.exit()
URL = str((sys.argv[1]))
os.chdir(savdir)
st1=URL.find("=")
nnname=URL[st1+1:len(URL)]
#nnname = filter(lambda x: x in string.printable, nnname)
# I am not sure if a character filtration is needed. This one above, doesnt work
# See help(yt_dlp.YoutubeDL) for a list of available options and public functions
ydl_opts = {}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(URL, download=False)
# ydl.sanitize_info makes the info json-serializable
dabon=(json.dumps(ydl.sanitize_info(info)))
#print(dabon)
puf1=dabon.find("riginal")
puf2=dabon.find("ttml",puf1)
puf3=dabon.find("https",puf2)
puf4=dabon.find('"',puf3)
murl=dabon[puf3:puf4]
webFile = request.urlopen(murl).read()
bah= str(webFile)
bah=bah.split('\\n')
wutt=""
for s in bah:
if s.find('style="s2">')>0:
s=s.replace(''',"'")
aw1=s.find('>')
aw2=s.find('<',aw1)
#print(s[aw1+1:aw2])
wutt=wutt+s[aw1+1:aw2]+"\n"
text_file = open(str(nnname)+".txt", "w")
n = text_file.write(str(wutt))
text_file.close()
What does this source code do ?
- first at all, it is not always possible to download the transcript of a youtube video directly. For example, if you use the dedicated option to do that with yt-dlp (that you need to have installed on your computer to be able to use this source code), you will notice that for this video you will get the content of the chat window (what people commented when the video was broadcast) but not the transcript of the author. So here, i extract the information of the video and i find the correct transcript in it. It will be the one in the original language.
- Then it downloads the transcript, format it and save it to the folder "source_documents" where PrivateGPT is installed.
You have to edit the code to put the location of the folder where PrivateGPT is installed your computer.
Transcripts may not always be available (for example, if the video is very new), then it will return an error.
- To use the code, i put it in a file (for example "extract.py") in the folder of PrivateGPT (it is more convenient) and i open a cmd prompt (with Windows)
- To use the code, i put the url of the video as an argument, for example:
python extract.py https://www.youtube.com/watch?v=A3F5riM5BNEThis should download and extract the transcript in the "source_documents" folder. Note that the resulting file doesn't have any timestamp anymore.
Once it is finished, type:
python ingest.pyand finally, type:
python privateGPT.pyAdd the option "-S", if you are not interested in the sources of the document referenced in the answers:
python privateGPT.py -SSo let's try, with the video i referenced above ( https://www.youtube.com/watch?v=A3F5riM5BNE )
query: what is this video about?
(and about one or two minutes later:)
answer:

(The answer that you may get yourself can change)
To be honest, it is far to be perfect and it's accuracy wouldn't be such a problem if the answers of privateGPT would get typed faster. Also the accuracy of the answers depends a lot on the questions.

(there is no mention of "super super easy" in the text, but there are 2 mentions of "super super")
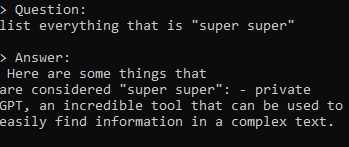
It is interesting to notice that it is not a literal answer.
Also privateGPT, can make accurate answers but mix the topics, so it cuts a bit the corners:

(That's why it is better to delete all the documents that are unrelated to what interests you. So, for what i have seen, it don't think it can handle very long text [now?])
Luckily you can still edit the .env file to increase the length of the answers:
(If you change any setting, i recommend you to delete the content of the "db" subfolder, and i use the ingest.py file again)
This is what i get, if i use "9000 tokens":

and this time it is a bit wrong...