Stable Diffusion is a tool to create pictures with keywords. Starting from a random noise, the picture is enhanced several times and the final result is supposed to be as close as possible to the keywords.
The thumbnail above links to a picture that has been generated starting from another picture hosted on Civitai , the goal of this tutorial is to provide ideas to retrieve the keywords with which the picture has been generated. The tutorial assumes that you have a functional version of Automatic1111 on your computer. It may work with other interfaces of StableDiffusion.
If you find a good picture and you know or guess that it has been made with Stable Diffusion, thanks to the keyboards with which the picture has been generated, you could:
- generate similar pictures
- use a part of these keywords because they render some particularly good results
- Or just confirm what was the intent of the author of the picture.
While I am certainly not an expert with Stable Diffusion, i found several methods to get or guess these keywords.
* Method #1 Use the PNGInfo panel of Automatic1111.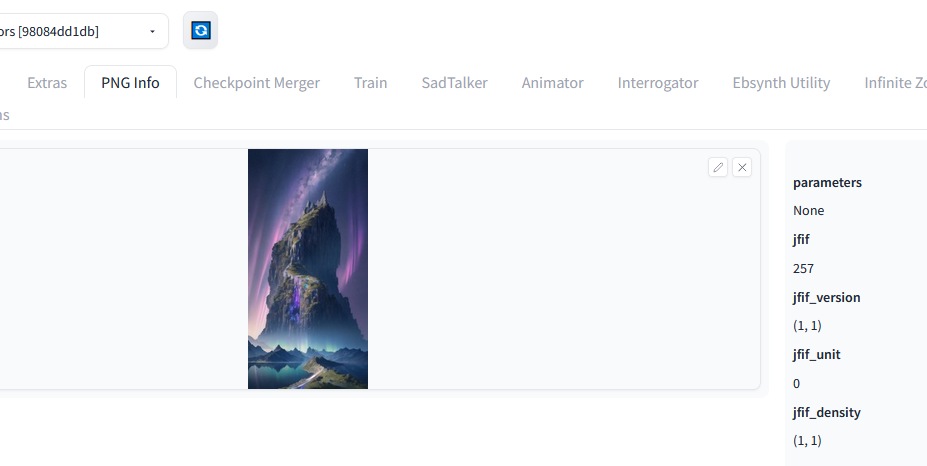
This screenshot of the PNGInfo panel of Automatic1111 has been taken after loading the thumbnail that you see in the introduction.
Where are the keywords, are you going to tell me ? Answer: they are not in the thumbnail, because they have been lost when the thumbnail was made.
But if I load the original picture in Automatic1111, you get this: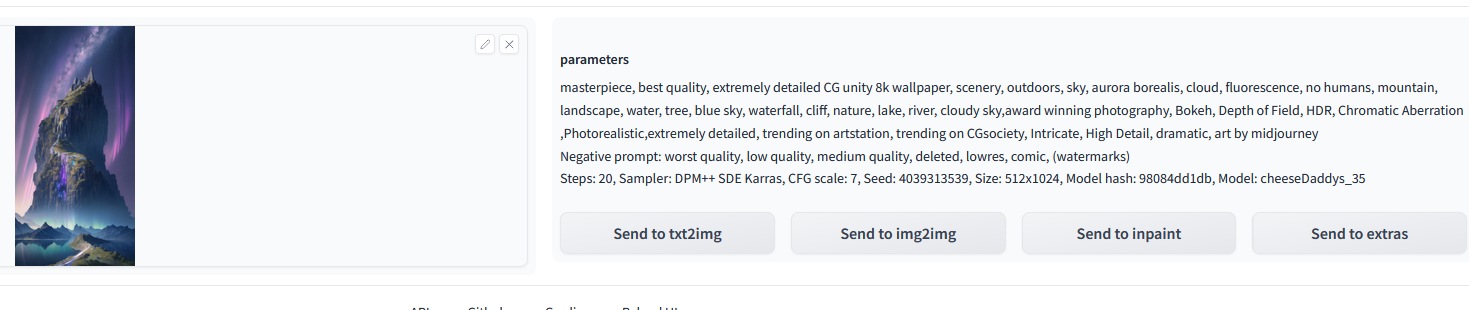
And here you have directly the results, including the seed with which the picture has been made.
The PNGinfo panel tries just to read the header of the png. There is no artificial intelligence or automatic1111 needed. The picture below is a screenshot of the hexadecimal view of Irfanview:
That's why automatic1111 can retrieve the data of the real picture, but not the data of the thumbnail!
* Method #2 try to find the source of the picture.
My second idea is to find the real source of the picture thanks to image search engines like Google image or Tineye to find the original source.
The source can be on a page that contains the keywords that have been used. For example, this page on Civitai contains the original picture that I've used myself as a reference (i modified some keywords) to create my own picture. Please note, that i used to exact same seed as the original file, to make my own picture look like the original one. You could also try to find similar pictures to find pictures that look alike.
If you don't find a webpage with the keywords maybe you can find instead, somewhere else, the original picture that hasn't been altered yet (see example #1 with the thumbnail and the original picture) with a usable header.
Indirect Methods
So until now, i tried to retrieve the original keywords that were used to generate a picture. Now i am going to show you 2 different methods to retrieve possible keywords. However these keywords don't produce outputs that are so close from the original picture.
Also i didn't find any way to retrieve the negative keywords.
* Method #3 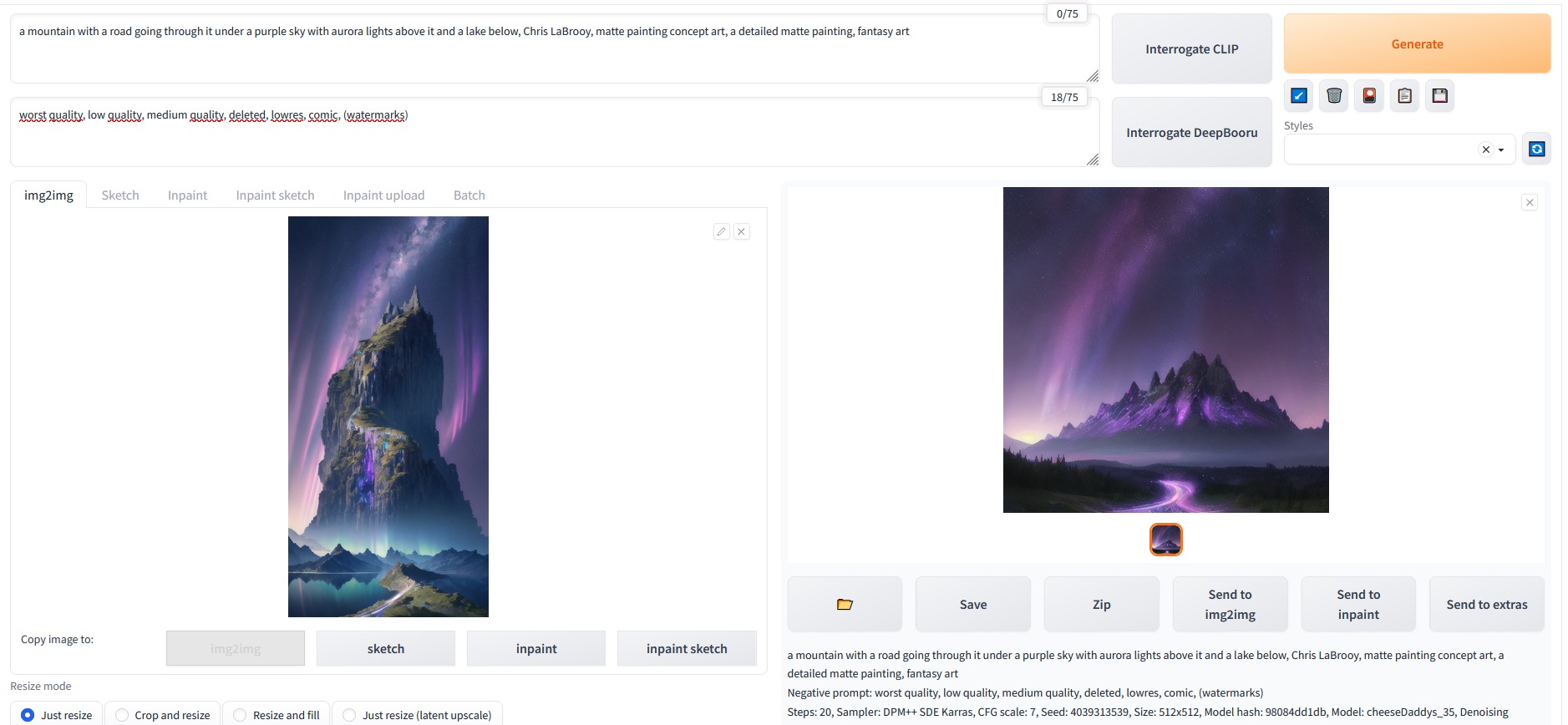
Click on the thumbnail above and see what i did:
- Go to the Img2Img panel of Automatic1111
- Load the picture on the left panel
- Click on interrogate CLIP. This returned this list of keywords that you can then see in the positive prompt:
"a mountain with a road going through it under a purple sky with aurora lights above it and a lake below, Chris LaBrooy, matte painting concept art, a detailed matte painting, fantasy art"
And that's all. To make sure that the picture looks alike:
- I kept the original negative prompt: they are pretty generic, so I don't think they matter that much
- I used the same seed as the original picture, the same sampling method and other data. I want to show how close we can go when the machine guesses what the picture is.
- Now if i do a generate, as i did on the picture above, i ll just generate the right picture that will be as similar as the "Denoising strength" (was set to 75% on the picture, which leaves 25% of the original picture).
To really use the data, you have to go to the Text2img panel and this is what i get, when i just change the positive prompt with the one that CLIP gives me: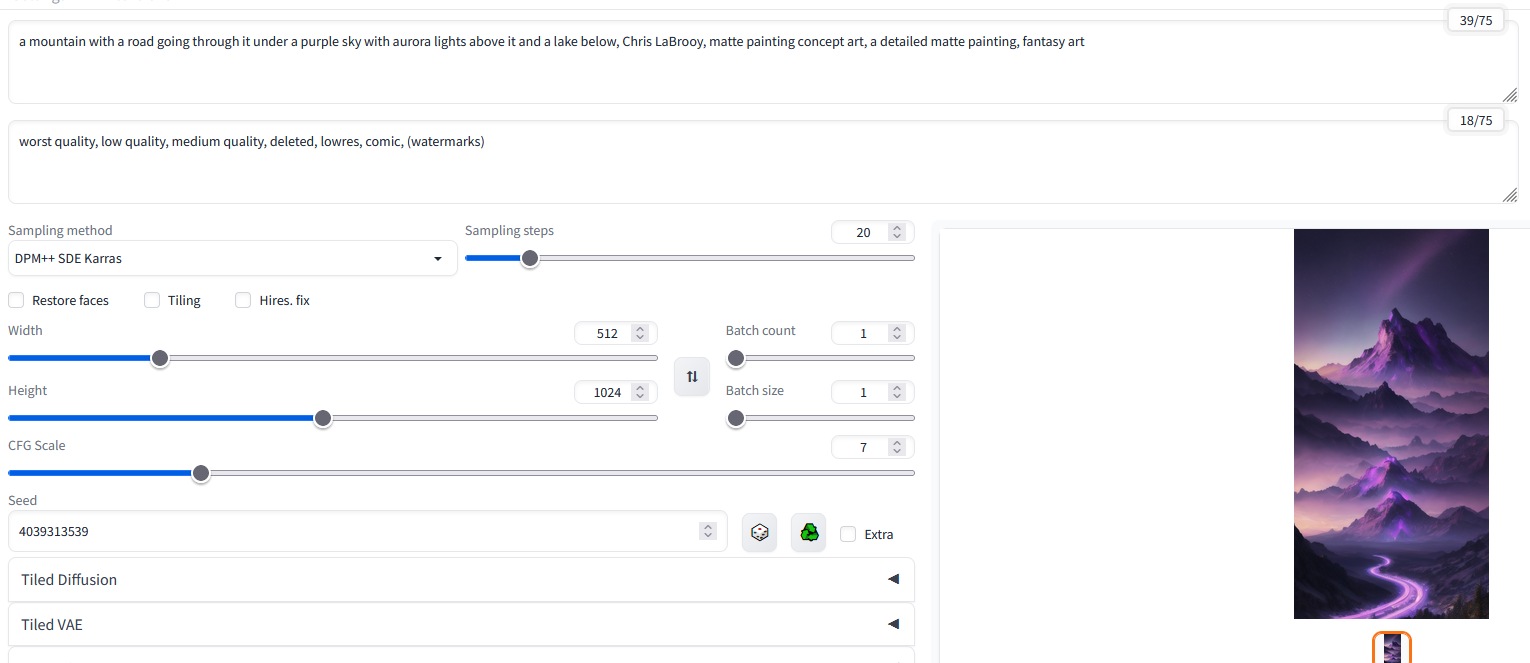
#3 bis
I can do exactly the same thing in the Img2Img panel and click on interrogate DeepBooru instead. This time i get this list of keyword (it is more a feature detection): bridge, building, city, city_lights, cityscape, cloud, cloudy_sky, fantasy, gradient_sky, horizon, landscape, light_particles, milky_way, mountain, mountainous_horizon, night, night_sky, no_humans, outdoors, purple_sky, scenery, shooting_star, sky, star_\(sky\), starry_sky, sunrise, sunset, tower, twilight, water
And this time, i can generate this picture:
Again i ve just changed the positive prompt to do the generation.
And as you can see, beside the color, the result is quite different.
#4 Alternative extension to find the keywords:
Go and install this extension to interrogate the picture: https://github.com/pharmapsychotic/clip-interrogator-ext from the extensions submenu.
There are several ways to interrogate a picture and you can use different models as a reference. To use another model in Automatic1111 to interrogate a picture, install the previously given extension and select the database that you want. The "about" panel of "Clip interrogator ext" gives you the best model to use. The "prompt" sub-panel will try to find the best keyword for you, while the "analyze" sub-panel can give you some additional hints on the words to use.
From the prompt sub-panel, i get these positive keywords with the VIT-L-14/openai:
a digital painting of a mountain with aurora lights in the sky, 2. 5 d cgi anime fantasy artwork, vertical, from arknights, blue and purple lighting, still from tv anime, artstyle andree wallin, symmetric matte painting, ffxiv heavensward, cgi art
For some reason, i experienced some difficulties to copy the keywords. "Unload" seems to help.
This is what i get in the txt-2-img prompt: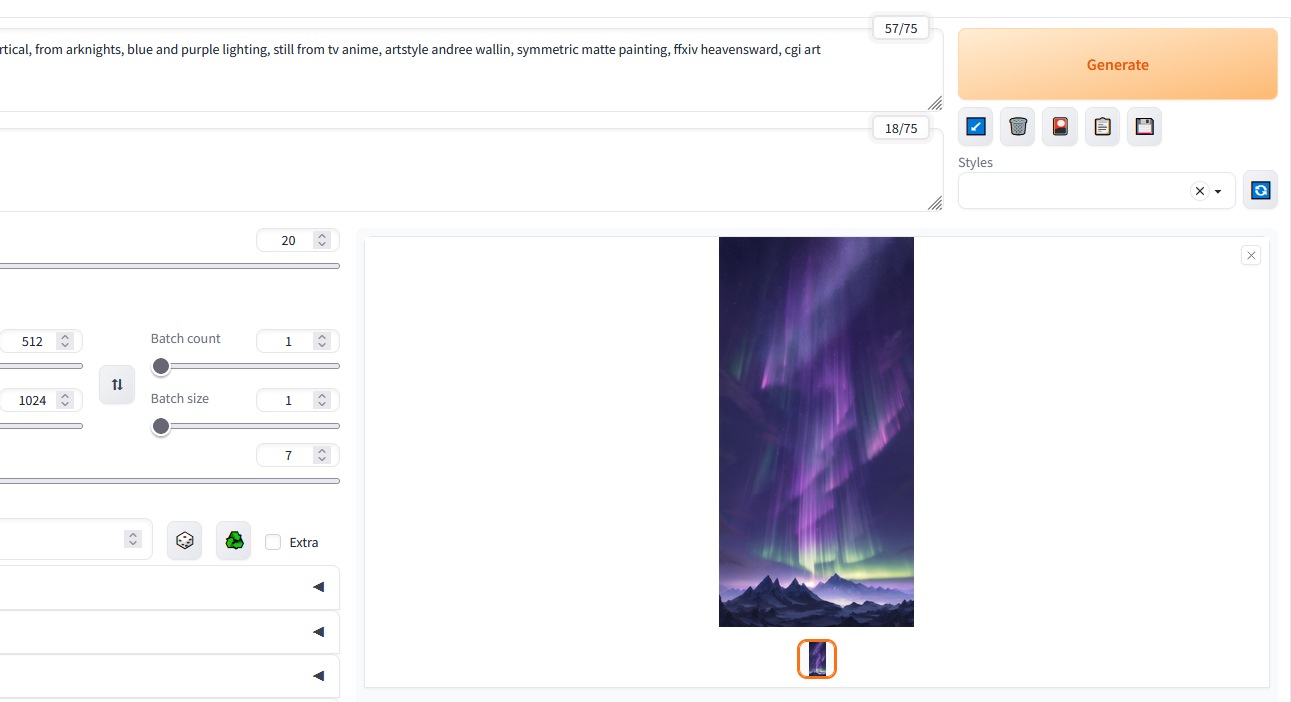
While you may disagree with the current example. It is with this current extension that i get the best results to make similar pictures.
Exercices:
#1: Use the keywords with which this picture has been created to find the intent of the author. Since this picture isn't real, you are not sure it is who you think it is. Can you tell objectively who it is supposed to be?
#2: Someone claims that he is very skilled with StableDiffusion and he uses this picture as an example. Is he using a good example ? Can you tell what is the last tool that has been used to create this picture ?