
Now that you have read my latest articles about Coqui_tts (here, here and here), you may maybe need some ideas about what to do with Coqui_tts.
Personally, when I code, my eyes are busy, but my ears are still available to do something else.
So thanks to Coqui_tts I can now use my computer to make it read what I can't read.
Here, my first idea was to use a link to a news on a website I am actually using (like yahoo news) to show a working example in real life... but... I probably don't have to right to use the resources of a third party website like that.
So for this kind of website, I am just going to publish a function, for educational purpose, to show how to do, but not a full code.
Respect the Terms of Service of the websites on which you use it.
Basically, your code is going to be in 2 parts.
One part that extracts the text you want to read on a website.
One that converts the extracted text (in a string of character) to an audio file.
We have already explained (more to the end of the page) how to use coqui_tts in a python code to generate a wav file.
Let's go back to the environment we have created here:
Open an Anaconda prompt
Type:conda activate coqui
And we are back to the python environment created for coqui_tts.
I've already given an example of code (more to the end of the page) to make coqui_tts create a wav file from a string of text, so I am just going to adapt a bit this code for the present situation.
What you need to have in the directory where you run the script below in this webpage, is a wav file named arnold.wav.
If you are missing the file, you can find it here:
https://github.com/oobabooga/text-generation-webui/tree/main/extensions/coqui_tts/voices
If you don't want to use this wav file, use the wav file of someone speaking at a sample rate of 22050Hz and it should be fine.
A wav file that is too long is not useful.
So basically in the code below, I want to read a string called "text_string", that I can attribute to what I want.
Then I do some tests to make sure I am actually using cuda (that requires a nvidia graphic card).
Then I convert my string of text to an audio file with one single line of function!
****# Import required modulesimport requestsimport sysimport torchfrom TTS.api import TTSprint(torch.version.cuda)text_string="Omg, I can read some text"print(text_string)# Get devicedevice = "cuda" if torch.cuda.is_available() else "cpu"print(">>>>>>>>>>> "+device)# List available TTS modelsprint(TTS().list_models())# Init TTStts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(device)wav = tts.tts(text=text_string, speaker_wav="arnold.wav", language="en")# Text to speech to a filetts.tts_to_file(text=text_string, speaker_wav="arnold.wav", language="en", file_path="output.wav")
****
The only difference between this example above and to read the text of a website is the fact that my string "Omg, I can read some text" (stored in the variable "text_string") is much shorter than the text of an average webpage.
My script tends to give warnings with actual webpage...:
"[!] Warning: The text length exceeds the character limit of 250 for language 'en', this might cause truncated audio."
... but I can't spot any difference between the audio and the original text file. I can't tell if I am just not attentive enough, but don't think so.
Does it matter ? I am not sure.
****
So now what I need is a function that can actually read the useful text of a webpage.
So personally I read yahoo news, which is a commercial website, with a lot of content, banners and so on.
So I am not going to parse the HTML code of the website, like I would have done it in the early 2000s where the HTML was much easier.
I am not exactly sure how is called the method that I am going to use to extract data from a document.
I think it is called Xpath https://www.zyte.com/blog/an-introduction-to-xpath-with-examples/
But I would call this personally "use the HTML elements" https://www.w3schools.com/js/js_htmldom_elements.asp
The link above shows an example in JavaScript, but you can adapt it in many languages.
-1 The idea to write the code is first to download an article, like this one:
https://finance.yahoo.com/news/49-1-warren-buffetts-373-110100214.html
If the page above gets offline, it should likely work with most of the news articles of yahoo news.
(At least as long as they keep their current structure of pages).
-2 Then I have to find a way to be able to call the HTML elements of the page.
Note that in the code below, "Xpath" is not a language as described above.
XPath is literally the "path" of the element, in the structure of the HTML file.
So basically, I was able to find a working example with the library lxml, so I have decided to adapt it to my code.
My knowledge of lxml is a bit limited, so it is possible that the code my code is not optimized.
-3 Then once the structure of the HTML file is loaded in the script, we need to find what we need and what is the best way to find it.
In reality, I use the development tools of the Firefox, but the developments tools of Chrome, would do a perfect job too.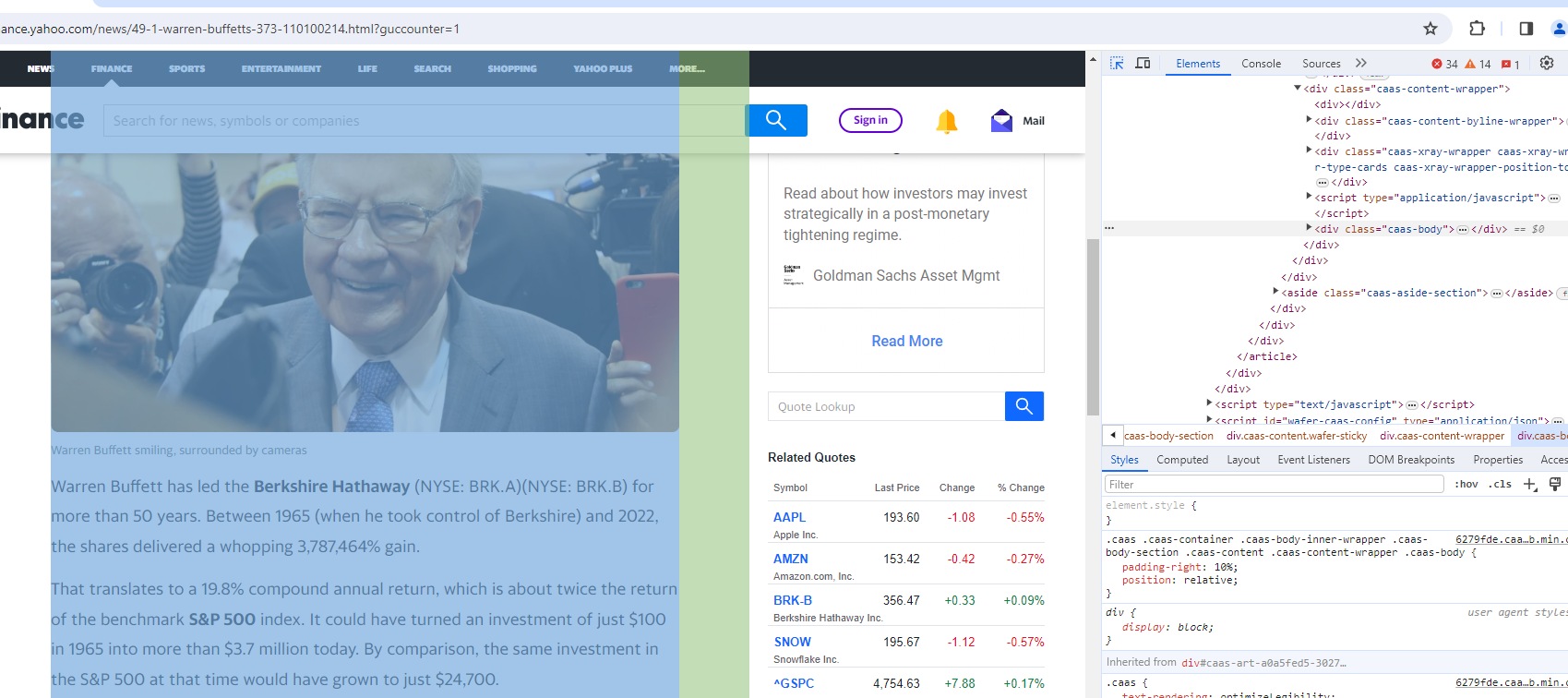
So using the arrow tool (see on the picture above):, the one that allows you to associate a design on the webpage to a piece of code, you try to find the best matching item for the area that interests you.
And with Firefox and with Chrome, I find that the beginning of the most interesting area is:
<div class="caas-body">
(Again check on the picture just above).
So if you check the HTML, you can see that this area has pictures and other codes and obviously, we don't want to read this.
Luckily there are some useful functions to handle this: we can for example, request the ".text_content()" of the element.
Oh btw, if you want to adapt my script to your needs, you should really read the documentation of "lxml".
Which is what my script uses.
Type it in your favorite search engine to read the docs.
Personally I find this page below very useful if you want to look for something that is loaded in lxml:
https://lxml.de/api/lxml.html.HtmlElement-class.html
I come to this code, below:
Note the presence of "sys.argv[1]" in the code: You have to call a URL that you want to read with the script (otherwise, you will get the error "list index out of range").# Import required modulesimport xml.etree.ElementTree as ETimport requests#from lxml import htmlfrom lxml.html.clean import Cleaner import lxml.htmlimport sys# Request the pagepage = requests.get(str(sys.argv[1])) # Parsing the page## to name parse.pyhtml=page.textcleaner =Cleaner(page_structure=False)cl = cleaner.clean_html(html)cleaned_html = lxml.html.fromstring(cl)#print(len(cleaned_html))classtofind="caas-body"compt=0for element in cleaned_html.xpath('/html/body'): dab=element.iter() for element2 in dab: if element2.tag=="div": if len((element2.find_class(classtofind)))>0: vall=element2.find_class(classtofind) for element3 in vall: if compt==0: beuh2=element3.text_content() #print(element3) print(beuh2) compt=compt+1##
You have to call the script like that:python parse.py https://finance.yahoo.com/news/49-1-warren-buffetts-373-110100214.html
With the url of the page you want to extract.
Then the script lists all the elements of '/html/body':
If the element is a "div", it asks if the class we want is present.
If yes, we ask for the text that can be written from this class and that's all.
Note that a same class can be listed in several nested "layers" of <div>, like <div><div><div class="caas-body">text text</div></div></div>
****
Extract the text of an article of joomla:
Now, it is pretty useless to use a TTS to read a webpage about coding, like the one you are currently reading, however, let's say you want to use a similar script for Joomla, to make it read an article:
So I find that the most useful unit for Joomla is:
class="com-content-article item-page"
Again it is in a "div", so I have just to change this single link that defines classtofind:
classtofind="com-content-article item-page"
With the code, above, it displays the content of the post, including the title and the intermediate text.python parsej.py "https://m14w.com/index.php?view=article&id=31:create-yourself-at-home-ai-generated-spoken-sentences-by-just-writting-some-text-and-a-reference-wav-file&catid=14"
(note the " double quote character at the beginning and the end of the url).
***
Extract the message part of VBulletin:
With Vbulletin, I would use this part:
class="conversation-content", again, in a div tag
This gives:classtofind="conversation-content"
For Vbulletin, I could tune it a little bit better to select just the username and the content of each message. Because here it reads the rank of the user, the join date, the number of posts and this takes time to read and it is very useless.
Of course, this code also doesn't login as user if it is needed to read the message.
When I tried with this webpage:
https://forum.vbulletin.com/forum/vbulletin-sales-and-feedback/vbulletin-pre-sales-questions/4484108-xenforo-to-vb6
It was able to get the messages, but I had a problem with the layout of the data.
When used with Coqui_tts, the filter does a decent job.
However, the extracted audio needs to be filtered even more, to get only what we care about.
This article is already long enough, so I am not going to fully adapt my code for Vbulletin (here), but it wouldn't be very long to do.