H2OGPT: Another tool to ask questions about your own documents
H2OGPT is related to the project H2OAI is a Web UI (which means web user interface) a bit like the oobagooba web ui.
In a matter of a saturday, this project went in my own ranking from "barely usable with poor result" to "pretty decent".
Advantages:
So basically H2OGPT is a bit an interface to ask questions to an LLM model like oobagooba, but you can also submit it your own documents and ask questions about them a bit like with privateGPT.
H2oGPT has several advantages on privateGPT:
- The interface looks better.
- You can tune the parameters of the model much better.
- It uses the graphic card (you need enough memory) and is therefore much faster.
- It also loads the models quite well.
- The team that takes care of their github is very reactive. So if you submit bugs, there is someone that listens.
- Interface can be accessed remotely
However it has several drawbacks:
- The policy of the web UI, states some limitations of use, that you could call censorship (don't ask questions that are too intimate or edgy).
- It is very important to parameter and select the models that you use carefully. Otherwise, you are gonna get some poor results.
- The GPU acceleration is only for Linux and didn't work (date: May, 29th 2023) with Windows when i tried it (at least i wasn't able to get it with a new conda environment).
Scroll down if you want to see some results when the model is asked some questions about a text.
Installation:
Here are some comments on the installation procedure that i used and that is based on the Github page of the project:
- 1st: I wouldn't install the project on a windows system, at least now. There is no advantage to do that. It is slower that privateGPT (now, because the GPU is not used) to ask questions about documents but censored unlike oobagooba, if you are looking for a text generator. Also right now, it returns many errors at various stages of the installation process with windows. But may be, it is just me that wasn't able to make it work.
- 2nd: Make a clean installation on a conda environnement (this suppose you have python and conda installed on your computer).
This is with Linux:conda create -n h2ogpt python =3.10.11source activate h2ogpt
- 3rd: Create a directory, where you want the project to be installed
- 4th: Clone the github project of h2ogptgit clone https://github.com/h2oai/h2ogpt.git cd h2ogpt
- 5th: install the basic requirements:pip install -r requirements.txt
Now if you start now the web ui:python generate.py --base_model=h2oai/h2ogpt-oig-oasst1-512-6_9b --load_8bit=True
You have a chatbot like oobagooba, based on the model h2ogpt-oig-oasst1-512-6_9b, hosted at huggingface.
So you need then to install the part that allows to ask questions about documents:pip install -r requirements_optional_langchain.txt
So if you do a:python generate.py --base_model=h2oai/h2ogpt-oig-oasst1-512-6_9b --load_8bit=True --langchain_mode=UserData
Later, you are going to be able to ask question to a document.
To do that, go to the "Data Source" panel, drop your file here, like explained (select it).
Then add the file or to userdata or to mydata (i don't know if there is a difference).
Then select the suitable "collection of sources", obviously userdata if you uploaded the file to userdata, and mydata if you selected mydata.
Then i click on "get source", then "show source":
Choose subset of Doc(s) in collection (click get source to update), make sure to select the documents that you want to use. Click on the cross to remove "all" if needed.
Then you can ask your questions if you want. However you will notice that the model h2ogpt-oig-oasst1-512-6_9b isn't that great to get answers on text (my opinion).
Here you may like to consider to use a "4bits" model, since it allows to use larger model with less memory.
To do that, you can try:pip uninstall peft transformers accelerate -y pip install -r requirements_optional_4bit.txt
but to be honest, i wasn't impressed by the performances and the results of the larger models (only a few numbers are available, i tried GPT-NeoX-20B), so first the moment, it is maybe not so interesting to do that.
Later you would have to replace the command --load_8bit=True by --load_4bit=True when loading the software.
So personally, the model junelee/wizard-vicuna-13b gave me acceptable results. Let's see them:
First please check this webpage and scroll down to see the questions i asked with privategpt.
If you want to do the same thing as me, please download this python script.
Edit it to correct the path where the transcript will be saved and use it to download the transcript of this youtube video: https://www.youtube.com/watch?v=A3F5riM5BNE
python ytcode.py https://www.youtube.com/watch?v=A3F5riM5BNE
Use:
Basically, i want to ask to H2oGpt the same questions, on the same file as i asked to privategpt, so it is possible to compare the answers.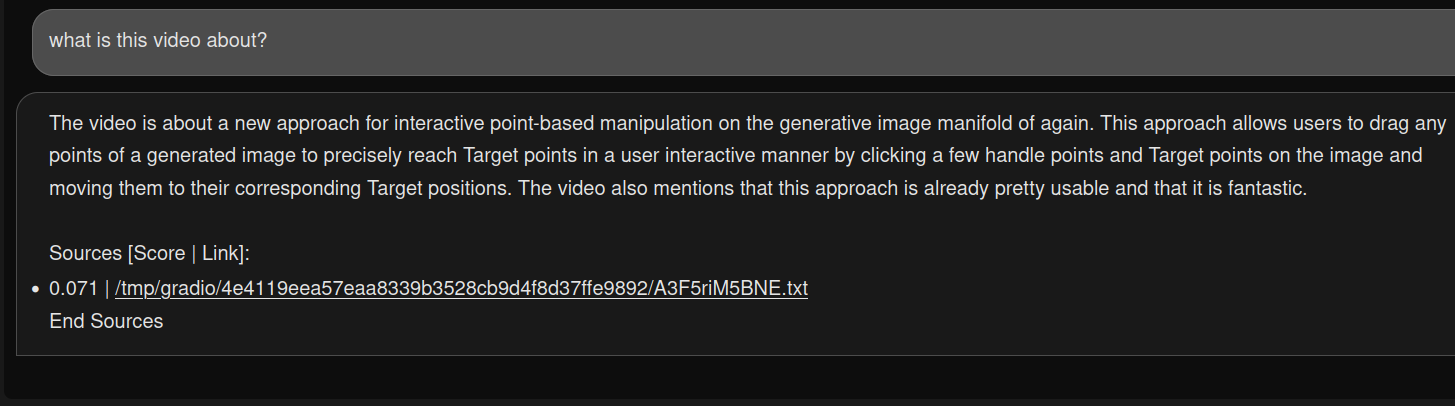
This answer above is not exactly right, the video was about privategpt and its author used it to summarize a scientific publication (about GAN, written "again" in the transcript).
It could be an answer to the previous question.
(Yes I had to ask ;) )
Actually, super super is used twice in the text: "this will basically use both your computer's power to accelerate the generation which is really super super useful" and "this tool is like super super powerful".
For the first sentence, i cannot retreive the answer, and for the second it is "privateGPT", the answer. I don't find the answer very right.
The answer is correct but a bit short. So i change the settings of the software, to get a better answer:

It is okay-ish, but some parts are missing, so i ask this question:
The first part of the answer looks like a hallucination.
And with other models ?
I wanted to show you the results of my question with another model but when I tried I got this 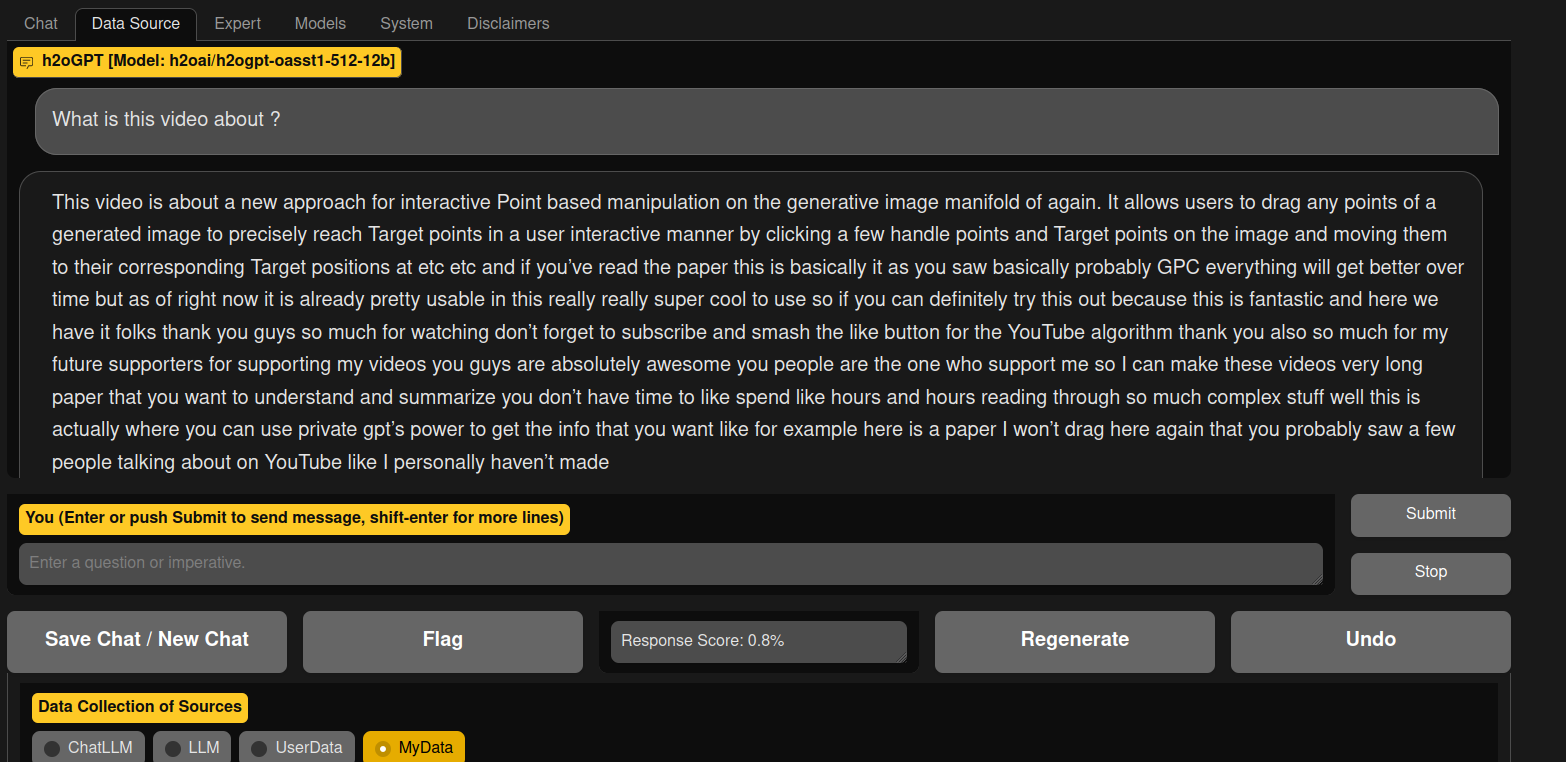
or this: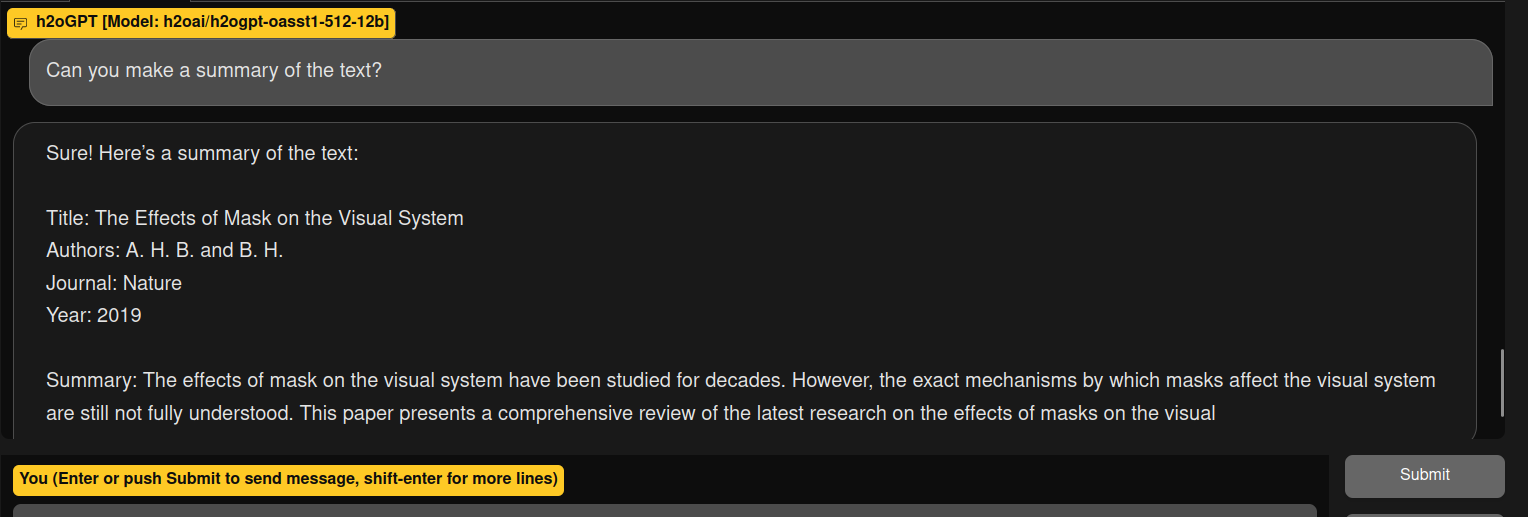
It is a bit weird because i was able to get average results with the model h2oai/h2ogpt-oasst1-512-12b
I suspect that this modification of the quality of the results can be related to the fact that i added the 4 bits support.
Conclusion?:
The results of h2ogpt are somewhat decent, quite fast, but are very much function of the model that you use. Make also sure to load the models correctly.
This articles may become obsolete very fast...